DP-600受験体験、DP-600テスト資料
Wiki Article
P.S.Xhs1991がGoogle Driveで共有している無料の2026 Microsoft DP-600ダンプ:https://drive.google.com/open?id=1YYbheyysjLyS99R71uMsjXq9shziSvHm
試験を受けることでMicrosoft認定を取得することを期待する人が増えています。ただし、多くの人にとって試験は非常に困難です。特に正しい学習教材を選択せずに適切な方法を見つけた場合、DP-600試験に合格して関連する認定を取得することはより困難になります。関連する認定を効率的な方法で取得したい場合は、当社のDP-600学習教材を選択してください。弊社のDP-600学習教材が試験に合格し、簡単に認定を取得するのに役立ちます。
Microsoft DP-600 認定試験の出題範囲:
| トピック | 出題範囲 |
|---|---|
| トピック 1 |
|
| トピック 2 |
|
| トピック 3 |
|
Microsoft DP-600テスト資料、DP-600的中合格問題集
DP-600認証試験に合格したいのは簡単ではなく、いい復習方法は必要です。我々はあなたに詳しい問題と答えがあるDP-600問題集を提供します。この問題集は我々の経験がある専門家たちによって開発されています。我々のすばらしいDP-600問題集はお客様の試験への成功を確保することができます。
Microsoft Implementing Analytics Solutions Using Microsoft Fabric 認定 DP-600 試験問題 (Q182-Q187):
質問 # 182
You have a Fabric tenant that contains a lakehouse named Lakehouse1. Lakehouse1 contains a table named Nyctaxi_raw. Nyctaxi_raw contains the following columns.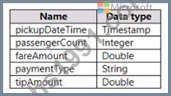
You create a Fabric notebook and attach it to lakehouse1.
You need to use PySpark code to transform the data. The solution must meet the following requirements:
* Add a column named pickupDate that will contain only the date portion of pickupDateTime.
* Filter the DataFrame to include only rows where fareAmount is a positive number that is less than 100.
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE:
Each correct selection is worth one point.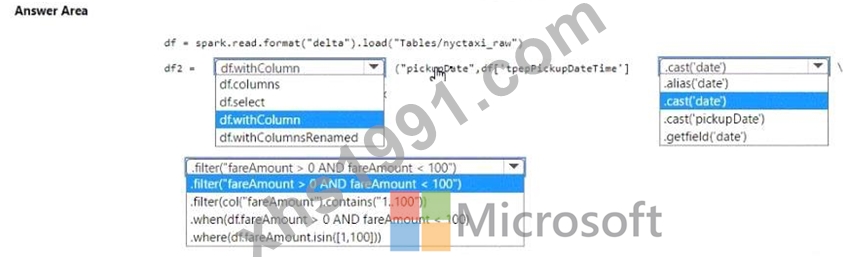
正解:
解説: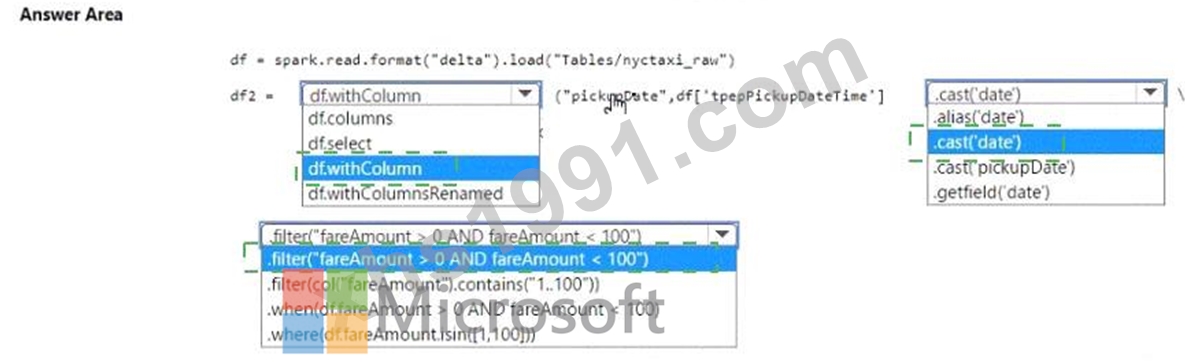
Explanation:
* Add the pickupDate column: .withColumn("pickupDate", df["pickupDateTime"].cast("date"))
* Filter the DataFrame: .filter("fareAmount > 0 AND fareAmount < 100")
In PySpark, you can add a new column to a DataFrame using the .withColumn method, where the first argument is the new column name and the second argument is the expression to generate the content of the new column. Here, we use the .cast("date") function to extract only the date part from a timestamp. To filter the DataFrame, you use the .filter method with a condition that selects rows where fareAmount is greater than 0 and less than 100, thus ensuring only positive values less than 100 are included.
質問 # 183
You have a Fabric tenant.
You plan to create a Fabric notebook that will use Spark DataFrames to generate Microsoft Power Bl visuals.
You run the following code.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
正解:
解説:
Reference:
Introduction to DataFrames - Spark SQL
Power BI and Azure Databricks
質問 # 184
You have a Fabric warehouse that contains a table named Staging.Sales. Staging.Sales contains the following columns.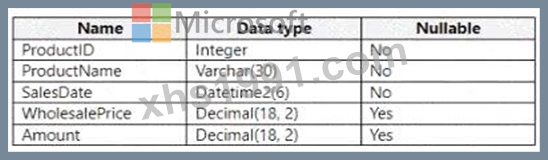
You need to write a T-SQL query that will return data for the year 2023 that displays ProductID and ProductName arxl has a summarized Amount that is higher than 10,000. Which query should you use?
- A.

- B.

- C.

- D.

正解:B
解説:
The correct query to use in order to return data for the year 2023 that displays ProductID, ProductName, and has a summarized Amount greater than 10,000 is Option B.
The reason is that it uses the GROUP BY clause to organize the data by ProductID and ProductName and then filters the result using the HAVING clause to only include groups where the sum of Amount is greater than 10,000. Additionally, the DATEPART(YEAR, SaleDate) = '2023' part of the HAVING clause ensures that only records from the year 2023 are included.
References = For more information, please visit the official documentation on T-SQL queries and the GROUP BY clause at T-SQL GROUP BY.
質問 # 185
You have a Fabric tenant that contains a lakehouse.
You are using a Fabric notebook to save a large DataFrame by using the following code.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
正解:
解説:
Explanation:
* The results will form a hierarchy of folders for each partition key. - Yes
* The resulting file partitions can be read in parallel across multiple nodes. - Yes
* The resulting file partitions will use file compression. - No
Partitioning data by columns such as year, month, and day, as shown in the DataFrame write operation, organizes the output into a directory hierarchy that reflects the partitioning structure. This organization can improve the performance of read operations, as queries that filter by the partitioned columns can scan only the relevant directories. Moreover, partitioning facilitates parallelism because each partition can be processed independently across different nodes in a distributed system like Spark. However, the code snippet provided does not explicitly specify that file compression should be used, so we cannot assume that the output will be compressed without additional context.
References =
* DataFrame write partitionBy
* Apache Spark optimization with partitioning
質問 # 186
You have a Fabric tenant that contains a workspace named Workspace! Workspace1 uses the Pro license mode and contains a semantic model named Model1.
You have an Azure DevOps organization.
You need to enable version control for Workspace1. The solution must ensure that Model 1 is added to the repository.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
正解:
解説: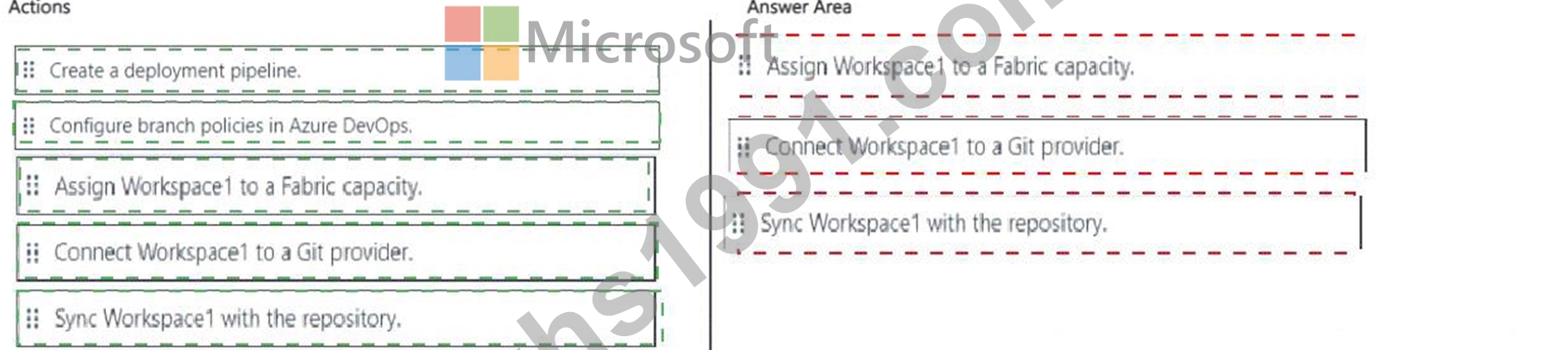
Explanation:
質問 # 187
......
Implementing Analytics Solutions Using Microsoft Fabric試験の質問は、競争で際立ったものにすることができます。何故ですか?答えは、DP-600証明書を取得することです。どんな証明書?証明書は、さまざまな資格試験に合格したことを証明します。試験は一晩で行われず、多くの人が適切な方法を見つけようとしているため、DP-600試験に時間と労力を費やす人が増えていることがわかります。幸いなことに、DP-600の実際の試験材料が見つかりました。これはあなたに最適です。
DP-600テスト資料: https://www.xhs1991.com/DP-600.html
- 有効的なDP-600受験体験一回合格-信頼的なDP-600テスト資料 ???? 時間限定無料で使える{ DP-600 }の試験問題は⏩ www.japancert.com ⏪サイトで検索DP-600日本語版サンプル
- DP-600専門知識 ???? DP-600問題無料 ???? DP-600関連復習問題集 ???? 検索するだけで➡ www.goshiken.com ️⬅️から【 DP-600 】を無料でダウンロードDP-600関連復習問題集
- DP-600受験体験を参照して - Implementing Analytics Solutions Using Microsoft Fabricを取り除きます ➖ ⮆ DP-600 ⮄を無料でダウンロード“ www.mogiexam.com ”で検索するだけDP-600受験準備
- 最高-実用的なDP-600受験体験試験-試験の準備方法DP-600テスト資料 ???? ➡ DP-600 ️⬅️の試験問題は【 www.goshiken.com 】で無料配信中DP-600日本語版対応参考書
- 信頼できるDP-600受験体験 - 合格スムーズDP-600テスト資料 | 実際的なDP-600的中合格問題集 ???? 検索するだけで➠ www.it-passports.com ????から⏩ DP-600 ⏪を無料でダウンロードDP-600受験準備
- 試験の準備方法-有難いDP-600受験体験試験-最新のDP-600テスト資料 ???? 《 DP-600 》を無料でダウンロード☀ www.goshiken.com ️☀️ウェブサイトを入力するだけDP-600関連復習問題集
- Microsoft DP-600受験体験: Implementing Analytics Solutions Using Microsoft Fabric - www.goshiken.com 簡単に勉強できるようにします ???? ☀ www.goshiken.com ️☀️の無料ダウンロード【 DP-600 】ページが開きますDP-600認証試験
- Microsoft DP-600受験体験: Implementing Analytics Solutions Using Microsoft Fabric - GoShiken 簡単に勉強できるようにします ???? ウェブサイト[ www.goshiken.com ]から➽ DP-600 ????を開いて検索し、無料でダウンロードしてくださいDP-600日本語復習赤本
- 最高-実用的なDP-600受験体験試験-試験の準備方法DP-600テスト資料 ???? ➡ www.topexam.jp ️⬅️で[ DP-600 ]を検索し、無料でダウンロードしてくださいDP-600専門知識
- DP-600日本語版対応参考書 ???? DP-600模擬問題集 ???? DP-600日本語復習赤本 ???? 今すぐ➥ www.goshiken.com ????で⇛ DP-600 ⇚を検索して、無料でダウンロードしてくださいDP-600オンライン試験
- 信頼できるDP-600受験体験 - 合格スムーズDP-600テスト資料 | 認定するDP-600的中合格問題集 ???? 最新⮆ DP-600 ⮄問題集ファイルは( www.mogiexam.com )にて検索DP-600模擬問題集
- adreayavf371478.dailyblogzz.com, cecilyjjfn923862.wikiannouncement.com, izaakjuvv934882.dgbloggers.com, social4geek.com, kianaurmr052065.yomoblog.com, www.stes.tyc.edu.tw, active-bookmarks.com, laytnbnlq209623.buyoutblog.com, ianwhwl131788.blog-mall.com, bookmark-vip.com, Disposable vapes
P.S.Xhs1991がGoogle Driveで共有している無料の2026 Microsoft DP-600ダンプ:https://drive.google.com/open?id=1YYbheyysjLyS99R71uMsjXq9shziSvHm
Report this wiki page